哈希表(Hash Table)
概览:
简单来说,哈希表是一种依赖哈希函数组织数据,以达到常数级别时间复杂度,插入和搜索都非常高效的数据结构。
两种哈系表:
哈希集合是集合数据结构的实现之一,用于存储非重复值。哈希映射是映射 数据结构的实现之一,用于存储(key, value)键值对。大多数高级程序设计语言标准库里都内置了哈系表模板。
1、哈希表的原理
哈希表的关键思想是使用哈希函数将键映射到存储桶。更确切地说,
当我们插入一个新的键时,哈希函数将决定该键应该分配到哪个桶中,并将该键存储在相应的桶中;当我们想要搜索一个键时,哈希表将使用相同的哈希函数来查找对应的桶,并只在特定的桶中进行搜索。示例
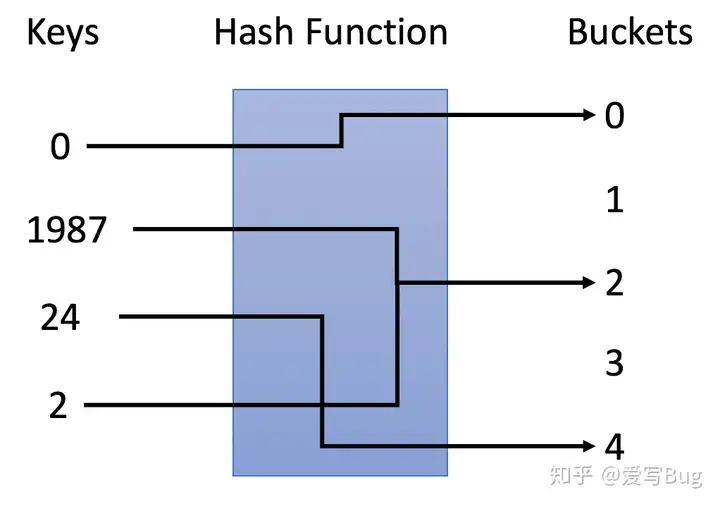
在示例中,我们使用 y = x % 5 作为哈希函数。让我们使用这个例子来完成插入和搜索策略:
插入:我们通过哈希函数解析键,将它们映射到相应的桶中。例如,1987 分配给桶 2,而 24 分配给桶 4。搜索:我们通过相同的哈希函数解析键,并仅在特定存储桶中搜索。如果我们搜索 1987,我们将使用相同的哈希函数将1987 映射到 2。因此我们在桶 2 中搜索,我们在那个桶中成功找到了 1987。例如,如果我们搜索 23,将映射 23 到 3,并在桶 3 中搜索。我们发现 23 不在桶 3 中,这意味着 23 不在哈希表中。哈希散列函数:
可以看得出元素存储位置与它的关键字建立了一个对应关系F,在查找时就可以由键通过哈希函数映射出元素的索引位置(桶),而对应关系F就是哈希散列函数。哈希函数是哈希表中最重要的组件,哈希表用于将键映射到特定的桶。上述示例中y = x % 5 作为散列函数,其中 x 是键值,y 是分配的桶的索引。
散列函数将取决于键值的范围和桶的数量。
下面是一些哈希函数的示例:
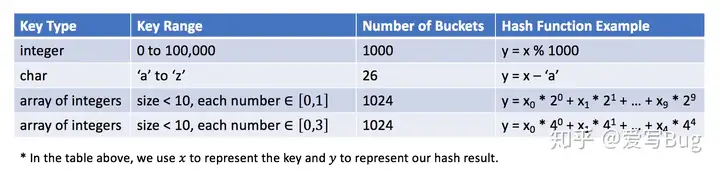
哈希函数的设计是一个开放的问题。其思想是尽可能将键分配到桶中,理想情况下,完美的哈希函数将是键和桶之间的一对一映射。然而,在大多数情况下,哈希函数并不完美,它需要在桶的数量和桶的容量之间进行权衡。
2、冲突解决
理想情况下,如果我们的哈希函数是完美的一对一映射,我们将不需要处理冲突。不幸的是,在大多数情况下,冲突几乎是不可避免的。例如,在我们之前的哈希函数(y = x % 5)中,1987 和 2 都分配给了桶 2,这是一个冲突(所以映射位置称之为桶,因为冲突时还需要在桶内作二次查找找到元素的位置)。
可以简单地使用一个数组将键存储在同一个桶中。如果 N 是可变的或很大,我们可能需要使用高度平衡的二叉树来代替。
3、复杂度分析
如果总共有 M 个键,那么在使用哈希表时,可以达到 O(M) 的空间复杂度。
而哈希表的时间复杂度与设计有很强的关系。
以使用数组来将值存储在同一个桶中为例,理想情况下,桶的大小足够小时,可以看作是一个常数。插入和搜索的时间复杂度都是 O(1)。
但在最坏的情况下,桶大小的最大值将为 N。插入时时间复杂度为 O(1),搜索时为 O(N)。
内置哈希表的原理
高级程序设计语言内置哈希表的典型设计是:
键值可以是任何可哈希化的类型。并且属于可哈希类型的值将具有哈希码。此哈希码将用于映射函数以获取存储区索引。每个桶包含一个数组,用于在初始时将所有值存储在同一个桶中。如果在同一个桶中有太多的值,这些值将被保留在一个高度平衡的二叉树搜索树中。插入和搜索的平均时间复杂度仍为 O(1)。最坏情况下插入和搜索的时间复杂度是 O(logN),使用高度平衡的 BST。这是在插入和搜索之间的一种权衡。
欢迎关注微.信公.众号:爱写Bug







